Support Vector Machines
The Support Vector Machine (SVM)
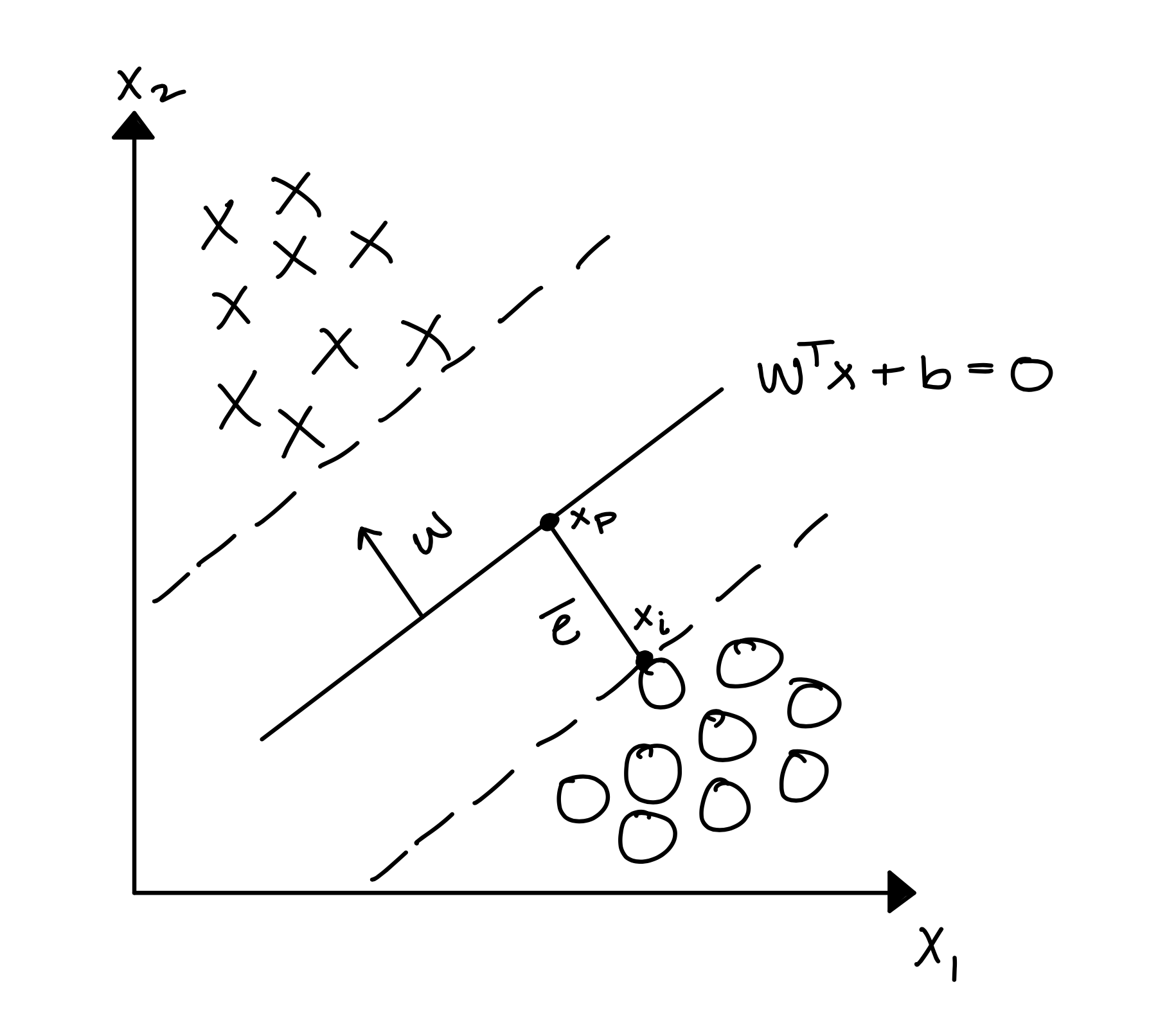
Other models for supervised learning of a binary classifier, such the Rosenblatt Perceptron algorithm, can guarantee convergence, but there is no guarantee on “how good” the hyperplane it will find is. The key insight that led to the derivation of SVMs was the idea that we would not only like our model to converge, but would like our model to give us the “best possible” hyperplane. Although, how does one define the “best possible” hyperplane? Well, SVMs define this as the hyperplane that maximizes the distance between the two binary classes. We will define this distance as the margin. Therefore SVMs try to maximize this margin.
The Margin
Given a dataset with binary labels , weights , and a bias , we define the margin as the distance from the hyperplane (given by ) to the closest point .
To formalize the definition of the margin lets first formalize the distance from the hyperplane to some point . First, notice that if we project onto we get another point denoted (see Figure 1) such that the distance from to the hyperplane is simply the distance between the two points. More formally, the distance from to is where .
Next, notice that because represents the minimum distance between and that it will also be orthogonal to and parallel to . Therefore we can rewrite as , for some unknown . Additionally, since we know lies on the hyperplane, then it must be true that . Using this fact, we can derive the following line of reasoning:
Now, we can use this definition of to rewrite the length as a function of , , and some :
Then finally, the margin given some hyperplane and dataset is given by:
Primal Form Derivation:
SVMs are a type of “margin maximizers”. That is, we want to maximize the . We can formalize this with the following optimization problem:
Notice one last thing, with this definition of the margin we could find some hyperplane that is infinitely far from out data that will satisfy this optimization problem. Therefore we must add an essential constraint that: . Using this, we once again rewrite the optimization problem as:
The above optimization problem is rather ugly, the maximization of a minimization with an inequality constraint does not look fun to optimize. Preferably we would like to simplify this by removing the inner minimization. To do so, notice that is scale invariant. That is, still defines the same hyperplane. Therefore, we can always find some such that . This constraint allows us to simplify the above objective as:
Then notice that if then it must be true that , and we can simplify our constraint even further:
As Kilian Weinberger once said, “maximization is for losers.” So notice that the maximization of the reciprocal of is just the minimization of . That is, we can rewrite our formulation as:
One last thing before we are done with the derivation of the SVM primal form. We cannot optimize as we need it to be twice differentiable where it’s currently linear. So we write out the final SVM primal form as:
This is the primal form of the SVM problem that we aim to optimize over.
The Lagrangian and the Karush-Kuhn-Tucker (KKT) Conditions
Consider the constrained optimization problem with inequality constraints in the form:
Such that and are convex, and is affine. We call this form the primal optimization problem where the number of inequalities is and the number of equalities is . Furthermore, we define the generalized Lagrangian of this form to be:
Such that and are the Lagrange multipliers. We would like to know when the generalized Lagrangian is equal to the primal form. To do this first consider two quantities. The first quantity:
Given this quantity we can consider two cases: The first case is when takes on a value that satisfies the primal constraints. In this case we can see that . In the other case, the case that violates the primal constraints, we will have . To formalize this we get:
Thus this form gives the same values of the primal form when satisfies the primal constraint. Therefore, we can write an equivalent statement to the primal form as the following:
Now lets consider the second quantity:
Then we define the dual of this form as follows:
Now lets compare these two quantities: Let be the optimal value of and be the optimal value of . Then if follows that because that:
This inequality is called weak duality where the difference is called the duality gap. This inequality is always true even under non-convex conditions. Though we would like know under what conditions strong duality () holds, this happens exactly when the duality gap is 0. By Slater’s theorem (I will not be proving it here) we can show that strong duality holds in the case that:
- and is convex. is affine.
- such that .
For the hard margin SVM, there is no equality constraint . We know that is convex and is affine and therefore convex. Therefore, Slater’s conditions hold under the assumption that such that , which is true if there exists some hyperplane that separates our data (as we will let ).
Under these conditions we will have some optimal values , , and that additionally satisfy the Karush-Kuhn-Tucker (KKT) conditions, which are as follows:
Dual Form Derivation:
The SVM primal form is a constrained optimization problem and can be solved using Lagrangian multipliers. Taking into account the above notes we let . Notice we do not have any equality constraints, then the Lagrangian of the SVM primal form is the following:
Considering the KKT condition #1, we take the partial derivatives w.r.t. and which gives:
Looking back at our original Lagrangian equation and plugging and in allows us to simplify:
Which leaves us with the final SVM Dual Form and the following optimization problem:
This SVM Dual Form will be the main focus of the practical implementation of
this algorithm as we can optimize this form using quadratic programming and
convex optimization libraries in Python such as CVXOPT
Deriving the Weights and Bias from the Dual Form
We already have a known solution for the weights that satisfies the KKT condition #1. That being: . Taking into account the KKT condition #3, notice that where . This leaves us with two main conditions, either is 0 and we are not dealing with a support vector, or in which case we are dealing with a support vector. We can ignore the case in which and deal solely with the case regarding the support vector. Simplifying the support vector case gives the following:
The equation above gives the bias for some support vector where . To find the bias of the hyperplane, we can just take the mean average over each support vector bias. Resulting in:
In most cases this will just equal the average over all support vector biases, though this will not always be true. In fact, I have seen multiple sources say that this is true and that the bias is equal to the mean over all support vectors biases, including myself at one point. Though I realized that if you have two points on one of your support vectors then taking the mean over all biases would skew your bias towards that support vector. So, you must be careful to only take the mean average over two bias terms (one on each support vector).
Python Implementation and CVXOPT
CVXOPT is a python library for convex optimization. It uses quadratic programming to solve the convex optimization problem of the following form:
We will use CVXOPT to build a Python implementation of the SVM. Much of the following code and design is modified from Aladdin Persson’s implementation (found here). His implementation of the SVM with CVXOPT was instrumental in my understanding, so a huge shout-out to him. Below I will show the core pieces of the code. The full code can be found on my GitHub.
import matplotlib.pyplot as pltimport numpy as npimport cvxopt
from mlxtend.plotting import plot_decision_regionsfrom sklearn.datasets import make_circles, make_blobsfrom sklearn.svm import SVCWe’re going to implement the SVM class in the traditional scikit-learn fashion taking the following abstract form:
class SVM: def __init__(self): self.X = None self.y = None
def fit(self, X, y): ...
def transform(self, X, y): ...To do this, let’s first implement the fit function. Though one problem does arise, we need to convert our dual form problem into something recognizable by CVXOPT. That is, we need to find a way to represent . To do this I followed this article, although I have also posted my hand-written notes on this conversion here. If we let , then after some tedious algebra we can represent , , , , , and as the following:
Where is an identity matrix of size , and where the size of is . In other words is how many samples of data we have. Given this, our fit function becomes the following:
class SVM: ...
def fit(self, x: np.ndarray, y: np.ndarray) -> None: m, n = x.shape
# Requires this shape and data type. y = y.copy().reshape(-1, 1).astype(np.float64)
self.X = x self.y = y
# Compute the inner product. self.kernel = np.dot(self.X, self.X.T)
# See my notes above for how this was derived. P = cvxopt.matrix(np.outer(y, y) * self.kernel) q = cvxopt.matrix(-np.ones((m, 1))) G = cvxopt.matrix(np.vstack((-np.identity(m), np.identity(m)))) h = cvxopt.matrix(np.vstack((np.zeros((m, 1)), np.ones((m, 1))))) A = cvxopt.matrix(y, (1, m), 'd') b = cvxopt.matrix(np.array([0]), (1, 1), 'd')
optimal = cvxopt.solvers.qp(P, q, G, h, A, b) cvxopt.solvers.options["show_progress"] = True
self.alphas = np.array(optimal['x'])Next, we need to write the predict function. For SVMs, this will follow very closely with the above section on deriving the weights and bias from the dual form, and then using them to make the prediction.
class SVM: ...
def predict(self, X: np.ndarray) -> np.ndarray: non_zero_alphas = (self.alphas > 1e-4).flatten()
support_k = self.kernel[non_zero_alphas, non_zero_alphas][:, np.newaxis] support_x = self.X[non_zero_alphas] support_a = self.alphas[non_zero_alphas] support_y = self.y[non_zero_alphas]
idx_0 = np.where(support_y == -1)[0][0] idx_1 = np.where(support_y == 1)[0][0]
bias_0 = support_a[idx_0] * support_y[idx_0] * support_k[idx_0] bias_1 = support_a[idx_1] * support_y[idx_1] * support_k[idx_1]
bias = -(bias_0 + bias_1) / 2
predictions = support_a * support_y * np.dot(support_x, X.T) predictions = predictions.sum(axis = 0) + bias
return np.sign(predictions)The full code, and it’s implementation can again be found on my GitHub. Now let’s test out the performance of our model on some fake data. We’ll also compare it against the scikit-learn implementation of the SVM.
# Get the toy dataset.X, y = make_blobs(n_samples = 200, centers = 2, random_state = 1)
y[y == 0] = -1y_int_32 = yy = y.reshape(-1, 1) * 1.0
# Our model.model = SVM()model.fit(X, y)
# sklearn implimentation for reference.sklearn_model = SVC(kernel = "linear")sklearn_model.fit(X, y_int_32)
# Visualize performance.fig, (ax0, ax1) = plt.subplots(1, 2, figsize = (8, 3))
plot_decision_regions(X, y_int_32, clf = model, legend = 2, ax = ax0)plot_decision_regions(X, y_int_32, clf = sklearn_model, legend = 2, ax = ax1)
ax0.set_title("Custom")ax1.set_title("scikit-learn")
plt.show()Which gives:
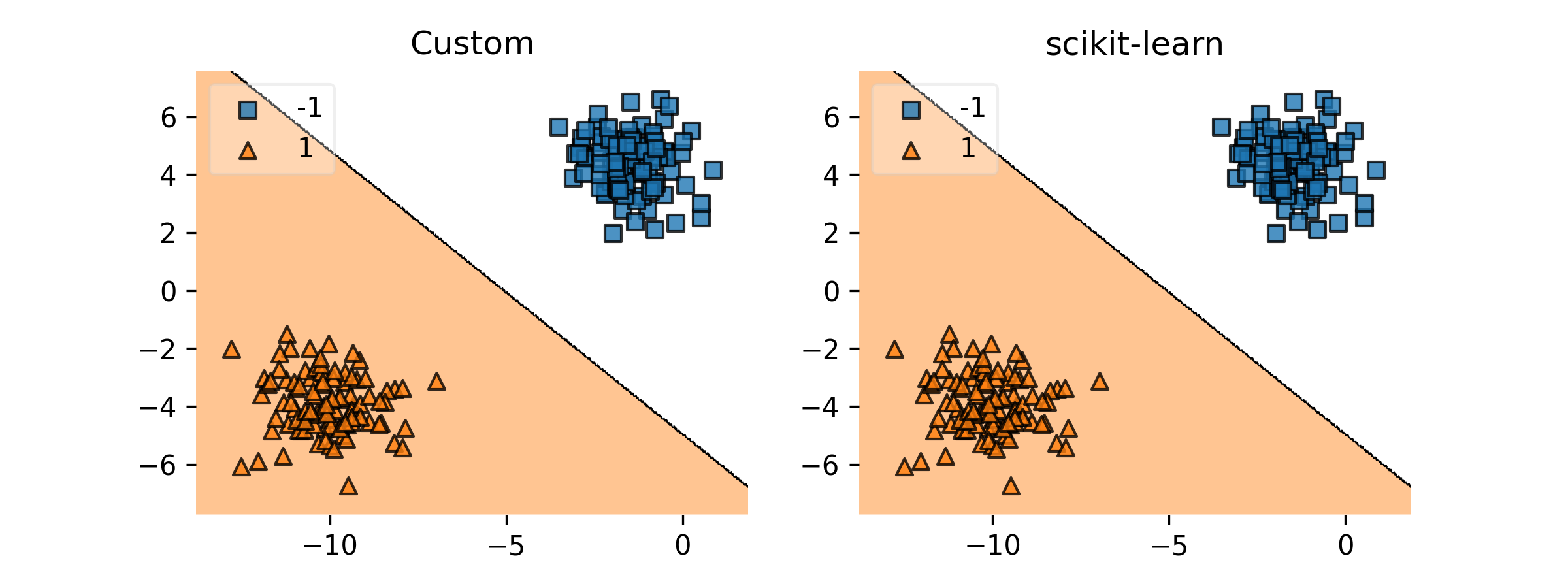
We can see that our model gives a nice separation of the data, and performs the same as the scikit-learn implementation.
Conclusion
In this post, we introduced the Support Vector Machine (SVM), a model for supervised learning of a binary classifier. We explored the mathematical foundations of SVMs, starting from the concept of margin maximization, and then derived both the primal and dual optimization forms. We also introduced and discussed the Karush-Kuhn-Tucker (KKT) conditions, and their role in solving the SVM optimization problem. Finally, we showed a practical implementation of an SVM in Python, using the CVXOPT library, and compared our implementation with scikit-learn’s.
References
- Cortes, C., Vapnik, V.N. (1995). Support-Vector Networks. Link
- Vapnik, V.N. (1997). The Support Vector method. Link
- M. S. Andersen, J. Dahl, and L. Vandenberghe. (2012). CVXOPT: A Python package for convex optimization. Link
- Persson, A. (2020). SVM from Scratch - Machine Learning Python (Support Vector Machine). Link
- Xavier, S. B. (2018). Support Vector Machine: Python implementation using CVXOPT. Link
- Andrew, NG (). CS229 Lecture notes. Link
- Weinberger, K. (2018). Lecture 9: SVM. Link
- Gordon, G., Tibshirani, R. (). Karush-Kuhn-Tucker conditions. Link
Figures
- Custom image.
- Example of the SVM and scikit-learn fit on a dataset. Link.